Test coverage je dôležitý nástroj, ktorý môžeme použiť na skvalitnenie našich unit testov. Je to jednoduchý koncept, ale často býva nepochopený. Pre programátorov môže byť pokrytie testami užitočný nástroj alebo strašiak. To prvé nastáva vtedy, keď vedia ako s pokrytím pracovať — aké sú jeho silné stránky, slabé stránky a na čo sa nehodí vôbec.
Strašiakom je vtedy, keď jedinú vec čo o pokrytí vedia je to, že je to „náhodne vygenerované” percento, ktoré treba prekročiť. Inak bude zle.
Poďme sa na túto problematiku pozrieť bližšie. V prvom rade, čo to je.
Spustením testu sa vykonáva kód v testovanom komponente. O riadkoch kódu, ktoré sa takto vykonali hovoríme, že sú pokryté testami. A súhrn všetkých riadkov, ktoré boli vykonané všetkými testami je „pokrytie kódu testami”. Zvyčajne sa vyjadruje číslom — celkovým počtom alebo percentom.
Takto to môže vyzerať (každé IDE alebo report vyzerá trošku inak, toto je príklad z Intellij IDEA).
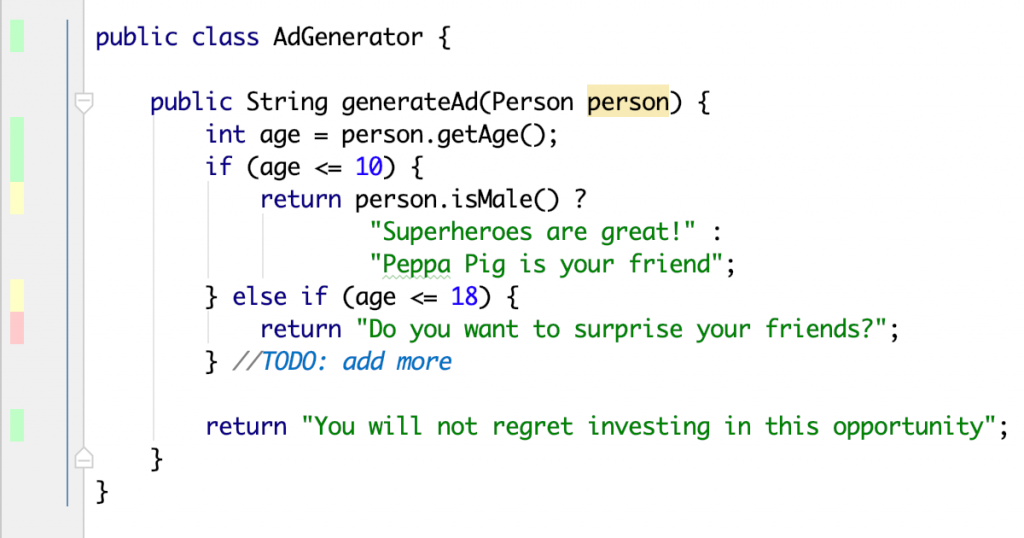
Všimnite si červený, žltý a zelený pásik naľavo. Červené riadky nie sú vôbec pokryté testom.
Kód bol vykonaný pri žltom riadku, ale výsledkom neboli všetky možnosti (zvyčajne pre if , switch a ternárny výraz). Toto je situácia, ktorá si zaslúži viac pozornosti.
Ako používam pokrytie ja
Pre mňa je pokrytie kódu testami nástroj, ktorým hľadám nepokryté miesta, ktoré si zaslúžia pozornosť. Či už potrebujem dopísať chýbajúce testy, alebo si overiť, že môžem bezpečne refaktorovať. Samozrejme, ak niečo nie je pokryté, tak to neznamená, že si to pokrytie zaslúži. Dôvody vysvetlím neskôr.
Pri mojich vlastných testoch pozerám na pokrytie komponentu v prípade, že som pri jeho vývoji nepoužíval TDD. Pomáha mi nájsť miesta, ktoré si zaslúžia dopísať testy. Ak som použil TDD, tak viem, že pokrytie je vysoké a nepozerám naň.
Ale mám ešte jeden spôsob použitia pre pokrytie testami. Pozerám na farebnú reprezentáciu pokrytia mojimi vlastnými testami. Pozriem na množstvo zelených riadkov a získam dobrý pocit. Neodsudzujte ma, skôr ako si to sami nevyskúšate — ako jednoducho sa dá zlepšiť nálada, prípadne prekonať tvorivý blok. Samozrejme, toto neskúšam na kóde, ktorého testy nepoznám.
Použitie pokrytia ako nástroj na posúdenie kvality testov sa mi zdá ako nezmysel. Dôvod je ten, že som (nie raz) videl testy, ktoré prešli 15 až 20-krát cez kód, ale potom výsledky neotestovali. To znamená, že keby som sa uspokojil s „dobrým pokrytím”, tak by som pri refaktoringu mohol zaviesť chyby, ktoré by mi tie testy neodchytili.
Aké situácie môžu nastať?
Podľa počtu testov, ich variability a počtu možných ciest v komponente môžeme mať nízke alebo vysoké pokrytie. Nerozdeľujem to na dobré a zlé pokrytie, lebo to závisí aj od iných faktorov. Napríklad, vygenerovaný kód (gettery, settery, konštruktory) nemusia byť pokryté vôbec a mne to nevadí.
Naopak, komplikovaná podmienka so sériou && a || si bude vyžadovať niekoľko testov aby bola pokrytá na 100 %. Pozor, 100 % nie je svätý grál, ktorý chceme dosiahnuť. Niekedy to ani nie je praktické alebo dokonca možné.
Kvalitné testy
Ak tím produkuje kvaitný kód a kvalitné testy (napríklad vďaka TDD), tak vyššie percento pokrytia má zmysel a nie je problém ho dosiahnuť.
Treba si uvedomiť, že zákon klesajúcich výnosov platí aj pri unit testoch a pokrytí. Paretovo pravidlo platí tiež. Takže rozumné percento pokrytia, ktoré má zmysel dosiahnuť záleží od toho, ako dlho bude trvať pridanie ďalšieho testu a akú má hodnotu (schopnosť odhaliť budúci problém).
Nezabúdajme ani na to, že existujúci kód treba udržiavať a komplikované testy môžu spomalovať pridávanie budúcich požiadaviek do komponentu.
Smoke testy
Na druhej strane spektra je skupina testov, ktorých zmysel je len naháňať vyššie percento pokrytia. Teraz nemám na mysli testy kódu čo je príliš jednoduchý aby ho bolo možné pokaziť (prípadne je vygenerovaný) ako gettery a settery.
Mám na mysli testy, čo vykonávajú serióznu biznis logiku, ale neoverujú výsledky. Prípadne overia niečo triviálne, ako že návratová nie je null. Tieto testy je podľa mňa najlepšie vymazať, hoci to zníži celkové pokrytie. Pretože tieto testy sú nebezpečné. Dávajú totiž falošný pocit istoty, že máme zabezpečenú budúcu kvalitu. Pritom väčšinou dokážu odhaliť len to, že komponent začne zlyhávať s neočakávanou výnimkou. To ale dokážu aj kvalitné testy.
Mám pocit, že takéto testy vznikajú najčastejšie preto, že firemné pravidlá žiadajú ich tvorbu, ale nie je na ne čas. To ide ruka v ruke s netestovateľným dizajnom.
Ak jediný spôsob merania kvality je pokrytie testami, tak ku dostatočnému výsledku sa najľahšie dostaneme vďaka smoke testom.
Premenlivé pokrytie
Niektoré komponenty môžu mať vyššie a niektoré nižšie pokrytie. Prakticky, podľa návratnosti investícií — aké ťažké je napísať kvalitný test a ako ľahké (pravdepodobné) je spraviť chybu.
Napríklad modelové triedy nemusia mať testované gettery a settery a v prípade, že neobsahujú biznis logiku, tak ich pokrytie je nulové. Ak aj nejaké pokrytie majú, tak je nepriame — z testov nejakej inej biznis logiky. Ak by sme chceli napísať pre ne testy, bolo by to veľmi jednoduché, ale zároveň aj strata času.
Naopak, komponenty určené na znovupoužitie majú mať vysoké pokrytie kvalitnými testami. Nie len, že to zabezpečí bezpečné použitie všade, kde sa používajú, ale súčasne to kladie nižšie nároky na testy volajúcich komponentov, ktoré už nemusia opakovať tie isté overovania.
Tento prístup sa mi zdá ako najlepšia voľba, pretože zohľadňuje dôležitosť komponentu a pravdepodobnosť vzniku problému. Na rozdiel od fixného daného čísla pre všetko.
Aké je praktické pokrytie komponentu, čo implementuje existujúci framework? Napísanie testov naň je zvyčajne komplikované (napríklad servlet API). Ja by som pravdepodobne ten servlet spravil ako tenkú vrstvu, čo premapuje parametre do doménováho modelu a odovzdá spracovanie inam. A nerobil preň žiadne extra testy.
Kombinácia unit a integračných testov
Dosiahnuť dobré pokrytie je ťažké — treba vytvoriť dostatočné množstvo unit testov. Ale veď máme aj suitu integračných testov… nevedeli by sme ich spojiť na získanie väčšieho pokrytia? Vedeli, ale zvyčajne to nie je dobrý nápad.
Ich kombináciou sa priblížime k nevýhode Smoke testov. Integračné testy zvyčajne testujú či aplikácia funguje dobre ako celok. Nesústredí sa na drobné detaily každého riadku, lebo to je úlohou unit testov. Ak unit testy nahrádzame integračnými testami, tak síce dostaneme vyššie pokrytie, ale žiadne overovanie kódu navyše. Ešte aj to očakávané vyššie pokrytie nemusí byť také vysoké ako sme dúfali. Prečo?
Pokrytie vlastne ukazuje koľko ciest v kóde bolo vykonaných. Keď zvyšujeme počet komponentov, ktoré testujeme spolu, tak počet ciest, ktorými môžeme prejsť, od začiatku po koniec, rastie exponenciálne. Na ich pokrytie musíme zvýšiť počet testov… exponenciálne. A všimli ste si, že napísať veľa integračných testov a doba, ktorú trvá ich vykonanie ich robí nepraktickými?
Toto nie je z mojej hlavy. Čítal som o tom už pred rokmi tu.
Vieme dosiahnuť 100 % pokrytie?
Sú komponenty, kde 100 % pokrytie testami je ľahko dosiahnuteľné. Ale aj v takom prípade by sme mali zvážiť, či návratnosť investície stojí za to. Nezabúdajme na zákon klesajúcich výnosov.
A sú také komponenty, kde sa ku 100 % pokrytiu nedostaneme. Niektoré konštrukcie jazyka, alebo vlastnosti štandardných komponentov nám to totiž neumožnia. Uveďme si 2 príklady z Javy:
enumaswitch— keď máme vo switchi pokryté všetky možnosti z enumu, tak nedokážeme otestovať vetvudefault. Tú tam chceme mať, lebo nás chráni pred chybou spôsobenou budúcim rozšírením enumu a zabudnutím pridania patričnéhocase. (Aby som bol presný, Heinz Kabutz to dokáže, ale túto techniku vám neodporúčam používať.)- rozhranie
Closeable— predstavte si, že v kóde používateByteArrayInputStream, ktorý chcete na konci zatvoriť. Metódavoid close() throws IOExceptionzdedila výnimku, ale táto implementácia ju vyhodiť nevie. Takže v teste ju nedokážete nasimulovať acatchnebudete mať pokrytý. (Vieme to obísť dizajnom, ale je veľký rozdiel v dizajnovaní na testovateľnosť a v dizajnovaní na dosiahnutie 100 % pokrytia).
V tomto momente by vám malo byť jasné, že je lepšie nesnažiť sa o dosiahnutie 100 % pokrytia. S výnimkou, keď nás platia za naše spokojné ego 😉.
Ako môžete využiť pokrytie pre seba?
Už som popísal, ako používam pokrytie ja. Je čas venovať sa využitiu pre vás. Tu je zopár nápadov, ktoré môžete použiť:
Nestrácajte čas nezmyslami ako 100 % pokrytie
Využite čas na niečo užitočnejšie. Buď na novú úlohu, alebo refaktoring.
Nevyčítajte manažmentu, že vyžaduje určitý stupeň pokrytia
Čo v skutočnosti potrebujú je kvalita, ale nemajú ju ako merať. Takisto nemajú ako merať produktivitu práce a návratnosť investície do pokrytia navyše. Efekt na kvalitu je nepriamy, ale je to lepšie ako nič.
Nestresujte sa, ak ste nedosiahli stanovené pokrytie
… ak to bolo z dôvodu, že to bolo ťažké, alebo ste na to nedostali dosť času. Ak vám to má spôsobiť konflikt s manažmentom, tak to je signál, že nerozumejú problému a je vhodný čas prehodnotiť pokračovanie na projekte. Lebo bude ešte horšie.
Naučte sa ako využiť pokrytie vo svoj prospech
Ale nie písaním smoke testov za účelom získavania vyššieho pokrytia. Použite ho na nájdenie miest, ktoré nie sú pokryté, alebo sú pokryté len jedným prechodom. Špeciálna situácia, ktorá si zaslúži pozornosť je komplikovaná podmienka, kde to vyzerá, že vetva je pokrytá celá, ale neboli vyskúšané všetky kombinácie výrazov.
Záver
Zatiaľ som explicitne neodpovedal na otázku v nadpise. Pravda je, že to neviem. Alebo ako hovoria konzultanti: „It depends”.
Toto vás asi neuspokojí, tak to skúsim inak. Pokrytie testami má viacej aspektov, ktoré musíme zohľadniť. A to je ťažké spraviť exaktne. Takže sa uspokojte so štandardne očakávanými 80 %. Ale nie na každú triedu, ale na modul či projekt. A nie ako nemennú hranicu, ale ako pohyblivý cieľ.
Bez merania, koľko stojí dosiahnutie daného pokrytia, prípadne objavenia korelácie medzi počtom chýb v komponente a jeho malým pokrytím, od vás predsa nemôžu žiadať viac. Ak áno, asi robíte na projekte, kde vedia trafiť do stanoveného cieľa naslepo. Alebo si to myslia.
„Vďaka mojim dlhoročným skúsenostiam s tvorbou unit testov a refaktoringom pomáham programátorom zmeniť ich postoj z musím na oveľa lepší — baví ma a dokážem.”